인덱스 스캔을 하면 무조건 빠른가 ? // NO
조건에 의한 처리범위가 넓어짐으로 인해 분포도가 나빠지는 경우가 있는데 이 경우 인덱스 스캔을 하는 것 보다는 FULL TABLE SCAN을 하는 것이 바람직함
-> FULL TABLE SCAN시엔 한 번의 I/O때 마다 여러 개의 데이터 Blocks을 처리하기 때문에 I/O횟수가 감소하게 됨
한 번의 I/O 4 Block Access Fast
DB_FILE_MULTIBLOCK_READ_COUNT=4 // 10 ~ 15% 이상 : 효율적
인덱스 사용이 불가능한 경우
1) NOT 연산자 사용
2) IS NULL, IS NOT NULL 사용
3) 옵티마이저의 취사 선택
4) External suppressing
5) Internal suppressing
옵티마이저의 취사 선택
옵티마이저의 자의적 판단에 의해서 인덱스를 사용할 수도 있고 사용하지 않을 수도 있는데,
이러한 것을 취사 선택이라고 함
| Rule Base Optimizer | Cost Base Oprimizer |
| 정해진 규칙 기준 | 비용 기준 |
Optimizer의 자의적 판단으로 인한 잘못된 선택을 강제로 제어하기 위해서 Hint 사용
External suppressing
1) 불필요한 함수를 사용한 경우
2) 문자열 결합
3) DATE변수의 가공
4) 산술식의 적용
5) lnternal suppressing
간단한 연산식 - comm + '500'
논리비교 연삭식 - bonus> sal /'10'
함수호출 MOD (sal,'100')

옵티마이저에 의한 선택 절차
특정 테이블에 대해서 SQL의 주어진 조건으로 인해 사용될 수 있는 인덱스가 두 개 이상인 경우
- 옵티마이저는 조건에 가장 적절한 인덱스를 선택해서 사용해야 함
- 주어진 조건에 가장 적절한 인덱스를 선택하려 할때 일련의 절차에 따라 결정함

옵티마이저의 인덱스 선택 시 판단 절차
1 주어진 조건에 대한 각 인덱스 별로 매칭률을 계산해 매칭률이 높은 것을 우선적으로 선택함

'='의 의미는 범위 제한
2. 인덱스 별 매칭률이 같은 경우에는 인덱스를 구성하는 칼럼의 개수가 많은 것을 우선적으로 선택함
3. 인덱스 별 매칭률과 인덱스를 구성하는 칼럼의 개수가 같은 경우에는 가장 최근에 생성된 것을 우선적으로 선택함
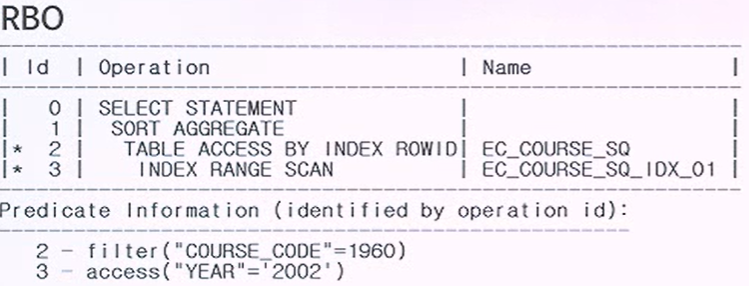
RBO와 CBO가 선택한 인덱스의 차이


최종 정리
1.인덱스를 사용하지 말아야 하는 경우
6블록 이상의 데이터를 가진 테이블에 대해서, 쿼리로 처리할 데이터가 전체 데이터 중 15%이상을 초과할 경우엔 인덱스를 사용하지 않는 것이 매우 좋은 성능을 냄
2.인덱스를 사용이 불가능한 경우
NOT 연산자와 비교
IS NULL,IS NOT NULL
옵티마이저에 의한 취사선택
인덱스 컬럼의 변형

'IT > DB' 카테고리의 다른 글
| [SQL] SORT/MERGE JOIN (0) | 2021.11.29 |
|---|---|
| [SQL] NESTED LOOPS JOIN 조인 (0) | 2021.11.29 |
| [SQL] 옵티마이저의 개념 및 종류와 인덱스 (0) | 2021.11.09 |
| SQL 튜닝 실행계획 및 옵티마이저 (0) | 2021.11.01 |
| tnsnames.ora 접속하는 방법 (0) | 2021.10.26 |